
Expérience professionnelle
Axa France
Lead Data Scientist • Décembre 2024 - Aujourd'hui
Data Scientist à la Direction Conformité, équipe Programmes & Opérations Sécurité Financière, encadrant une équipe de rôles data au sein du métier.
Environnement technique : Databricks, Spark, Azure Devops, Python
Sujet : Création d'un algorithme de filtrage et criblage des bases clients contre des listes de personnes sous sanctions, personnes politiquement exposées ainsi que d'autres scénarios à des fins de Lutte Contre la Fraude et Financement du Terrorisme.
Résultats : précision du filtrage à 97% sur les benchmarks de marché, contre 82% pour l’ancien outil.
Orange Cyberdefense
Lead Data Scientist (Consultant) • September 2023 - Octobre 2024
Environnement technique : GCP (Kubernetes, Helm, Terraform), Python (Scikit-learn, PyTorch, MLflow, Airflow, FastAPI, Celery)
Création et management d'une infrastructure de détéction de site de phishing scalable avec GKE (Kubernetes) en utilisant Terraform et Helm pour automatiser le provisionnement et le déploiement.
Entrainement d'un modèle en utilisant texte, images et structure des pages web pour déterminer leur niveau de risque.
Mise en place d'un workflow ML automatique avec MLFlow et Airflow pour versionner les modèles et orchestrer les tâches.
Résultats : Orange Cybersecurite.
Kereon Intelligence
Data Scientist • Novembre 2020 - Août 2022
Missions :
Hackathon IMA Innovation, 2022
Contexte : Hackathon IMA Innovation.
Résultats : Deuxième place.
Sujet : "Amélioration d'un modèle de prévision en fonction de données météorologiques".
🌩🌧Notre activité étant très fortement soumise aux aléas climatiques, nous souhaitons améliorer notre modèle de prévisions en fonction de celles-ci.
L’équipe a réalisé un zonier sur les différents risques représentés dans le portefeuille (tempête, inondation, etc.), et un modèle de prédiction climatique sur 10 jours.
Combiner le zonier et le modèle permet pour chaque zone d’anticiper la charge de travail sur les plateformes d’assistance.
Par exemple, notre modèle permet de prévoir le staffing nécessaire pour une zone à fort risque pour une semaine donnée, en anticipant une tempête.
Projet Interne, 2022
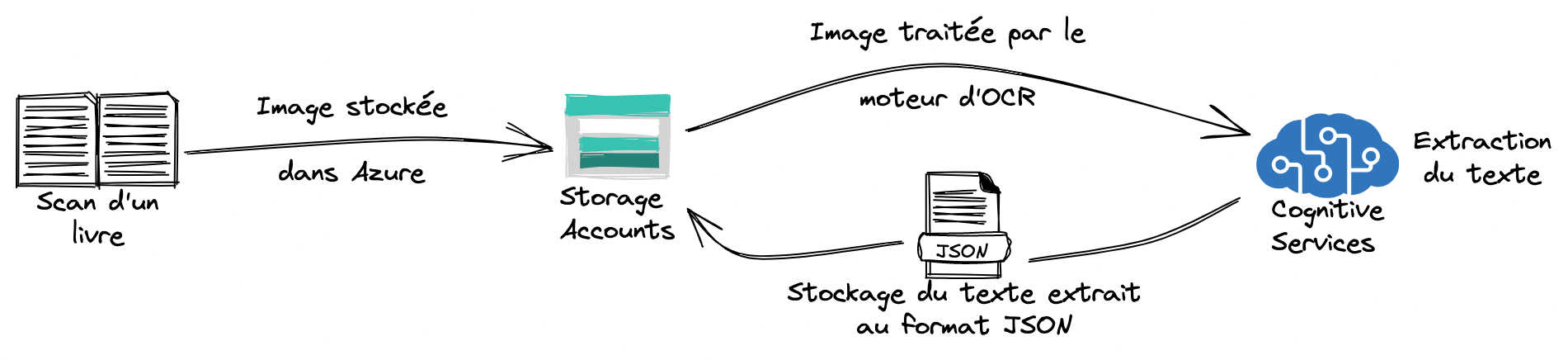
Contexte : projet d'extraction de texte de scan de livres.
Le projet à consisté à réaliser l'extraction de texte à partir de scan de livres.
Le projet a été réalisé en environnement Microsoft Azure. Les images étaient dans un premier temps stockées dans un storage account, puis traitée par une brique d'OCR. Les résultats étaient enfin stockés au format JSON dans le storage account.
MNCAP, 2021 - 2022
Contexte : organisation data et Solvabilité II.
Pour poursuivre l'objectif d'améliorer leur organisation data, MNCAP souhaitait effectuer un état des lieux par les biais d'un cas d'usage : le calcul d'indicateurs clés nécessaires à la production de rapports prodentiels dans le cadre le Solvabilité II.
L'étude de ces cas d'usage a permis de créer le data lineage de ces indicateurs et d'assurer leur tracabilité et leur exactitude.
MACIF, 2021 - 2022
Contexte : création d'une base de données permettant d'alimenter un reporting de pilotage à chaud en temps réel.
Environnement technique : SQL, Python
Défi :
Dans l'optique de suivre sa production et sa gestion des sinistres, le groupe MACIF souhaitait créer un tableau de bord de pilotage à chaud en temps réel permettant d'agréger les indicateurs les plus importants.
La difficulté a résidé dans l'agrégation de différentes sources de données peu cohérentes entre elles dans une seule base permettant le calcul des indicateurs souhaités.
Dans un souci d'optimisation, une fois les données récupérer, les indicateurs ont été calculés directement côté base de données avant d'être chargées vers la solution de BI.
Solution :
Une première partie d'agrégation des sources de données a été nécessaire.
Dans un second temps, le calcul des indicateurs directement en SQL à représenté le gros du travail (une centaine de scripts).
Enfin, pour la mise en production, les sujets de purge automatiques, déclanchements des scripts, etc. ont dû être abordés.
Ocean Hackaton, 2021
Contexte : organisation du Ocean Hackathon en partenariat avec le Village By CA.
Page de l'événementIl s'agit d'un événement centré autour de l'innovation dans le domaine de l'océan, la mer et tout le pourtour côtier français, ainsi que d'autres pays participants.
La ville de La Rochelle a accueilli cette année 8 défis.
Mon rôle a été celui de Coach Data en amont de l'événement et le temps du week-end pour guider les participants sur les sujets de gestions et utilisation des données.
CTF, 2021
Contexte : Organisation d'un événement dans le domaine de la sécurité informatique.
J'ai créé un ensemble de challenges liés à la data science dans le cadre du CTF.
Excelia Business School, 2021
Contexte : création d'une formation "Data For Business".
Réalisation de supports de cours, de contenu pédagogique et de validation des acquis dans le cadre d'une formation généraliste d'acculturation à la data.
Ma contribution concerne les modules :
- Comprendre les données
- Les agrégation de données
- Les disciplines de la data
Territoria Mutuelle, 2021
Contexte : réaliser une optimisation de la stratégie d'allocation d'achat de mots clés Google Ads.
Cet objectif s'inscrit dans une chantier plus large concernant la data gouvernance. En effet, Territoria Mutuelle voulait corréler le mot de recherche GoogleAds avec le type de client et la qualité de son expérience.
La réalisation de cet objectif est passé par une revue de la gestion de la donnée chez le client. Un audit a été conduit sous forme d'ateliers itératifs pour réaliser une cartographie fonctionnelle / applicative et un modèle de données.
Cette étude de l'existant a permis d'identifier des chantiers d'innovations et d'amélioration : l’amélioration de l’architecture data et de sa gouvernance.
La finalité du projet a été une Feuille de Route Data et un Dossier de Solution. L’information a été désiloté en créant une architecture Data Centric. Des passerelles ont été créé entre les silos de bases de données. Ce travail a posé les bases d’une culture data pour orienter le pilotage futur.
Bak, 2021
Contexte : conseil Data engineering / Acting CTO.
le projet Bak a pour but de créer une plateforme permettant de faciliter la sécurisation rapide d'un voyageur pour les différentes pathologies (besoin d'un médecin généralise, suivi de maladie chronique) à l'étranger. Cette platforme est un compagnon de voyage donnant accès à des fonctionnalités de recherche d’un professionnel de santé, géolocalisation, prise d’information géopolitiques locales.
Cerfrance, 2021
Contexte : créer un flux de données de l’extraction automatisée jusqu'au reporting.
Environnement technique : Python, Flask, GraphQL
Défi :
Cerfrance souhaitait créer un flux de données automatisé entre sa base de données et son nouvel outil de reporting.
Le travail a consisté à créer un «pont» entre la base de données et l’outil en extrayant les données en suivant des règles automatiques (trigger à l’insertion d’information dans la base)
Puis création d’un web-service pour permettre de lancer certains traitement «à la main».
Enfin le programme a été complété en implémentant des fonctionnalités de sauvegardes distantes (vers FTPS) et d’envoi de mail automatique (SMTP).
France Active, 2020
Contexte : modélisation de risques dans le cadres de prêts.
Environnement technique : Python
Défi :
France Active accorde des prêts dans le cadre de création d'entreprises crées pour des personnes cherchant un retour à l'emploi. Chaque projet doit être évalué en termes de risques et scorés.
Solution :
Le travail a consisté à créer un brique de traitement des données pour entraîner un modèle de prédiction de survie sur l'historique de France Active. Ce modèle a été intégré à l'applicatif pour pour obtenir un score à partir d'un nouveau projet.
Valeur ajoutée :
Le nouveau modèle est plus performant est fiable que le modèle historique qui était plus simple et n'apportait plus satisfaction.
AddixWare
Data Scientist • Novembre 2019 - Novembre 2020
Missions :
LVMH, 2020
Contexte : modélisation d'une grandeur physique (point éclair) de cosmétiques pour répondre à un cahier des charges.
Environnement technique : Python, TADA
Défi :
Modélisation du point éclair dans des produits cosmétiques à partir de leur composition.
Solution :
Application de méthodes statistiques et de machine learning pour analyser et prédire le point éclair.
MyDataModels, 2020
Projet :
Rédaction d'un livre blanc sur le thème de l'évaluation des modèles issus du machine learning en classification binaire, multi-classes et en régression.
Covid-19, 2020
Contexte : Covid-19.
Environnement technique : Python
Dans le but de rédiger une série d'articles sur le covid-19, l'étude a concerné les facteurs aggravants du covid-19 : travail sur une base de données sur la propagation du virus en Chine et au Mexique pour analyser les causes et obtenir un diagnostic.
MyDataModels, 2019 - 2020
Défi :
MyDataModels développe sa solution de machine learning compacte, avec une interface simple, permettant de répondre à des besoins assez large.
Le développement de l’algorithme de machine learning proposé dans cet outil est en constante évolution et fait l'objet d'un travail de R&D.
Mon rôle :
Le travail effectué concerné le benchmarking de la solution dans des cas extrêmes de faible nombre d’observations et de fort nombre de variables.
Une deuxième partie a concerné l’adaptation de l’algorithme a des problématiques de séries temporelles.
Valeur ajoutée :
Etude des limites de la solution.
Sanofi Pasteur, 2019 - 2020
Contexte : accompagnement en data science sur deux projets.
Environnement technique : Python, TADA
Travaux d'accompagnement, d'aide et de conseil pour la création d'un processus industriel breveté de production de vaccin et même travaux pour des travaux de séquençage de virus.
Magellan Consulting
Data Scientist • Mai 2019 - Août 2019
Missions :
Crédit Agricole, 2019
Contexte : travaux de cadrage de refonte de la gestion des connaissances à l'échelle Groupe.
Défi :
Dans le contexte d'un grand chantier concernant sa gestion des connaissances, le groupe Crédit Agricole avait besoin de réaliser un état des lieux du fonctionnement du stockage et de l'utilisation des documents dans chacune de ses branches.
Solution :
Un grand nombre d'entretiens ont été menés avec les directions des différentes caisses régionales et des pôles métiers pour rentrer en profondeur dans la gestion des connaissance à l'échelle la plus fine. L'objectif a été de mapper les connaissances, détecter des redondances d'informations ainsi que les informations qui n'étaient pas synchronisées ou mises à jour.
Projet interne, 2019
Contexte : travaux internes sur le thème des services cognitifs en machine learning: computer vision (Convolutional Neural Network).
Environnement technique : Python, TensorFlow, Android Studio
Défi :
Réalisation d'un POC dans le domaine de la computer vision pour l'appliquer à différents domaines.
Solution :
La première réalisation a été une formation, d'acclimatation à la data science et en particulier à la computer vision.
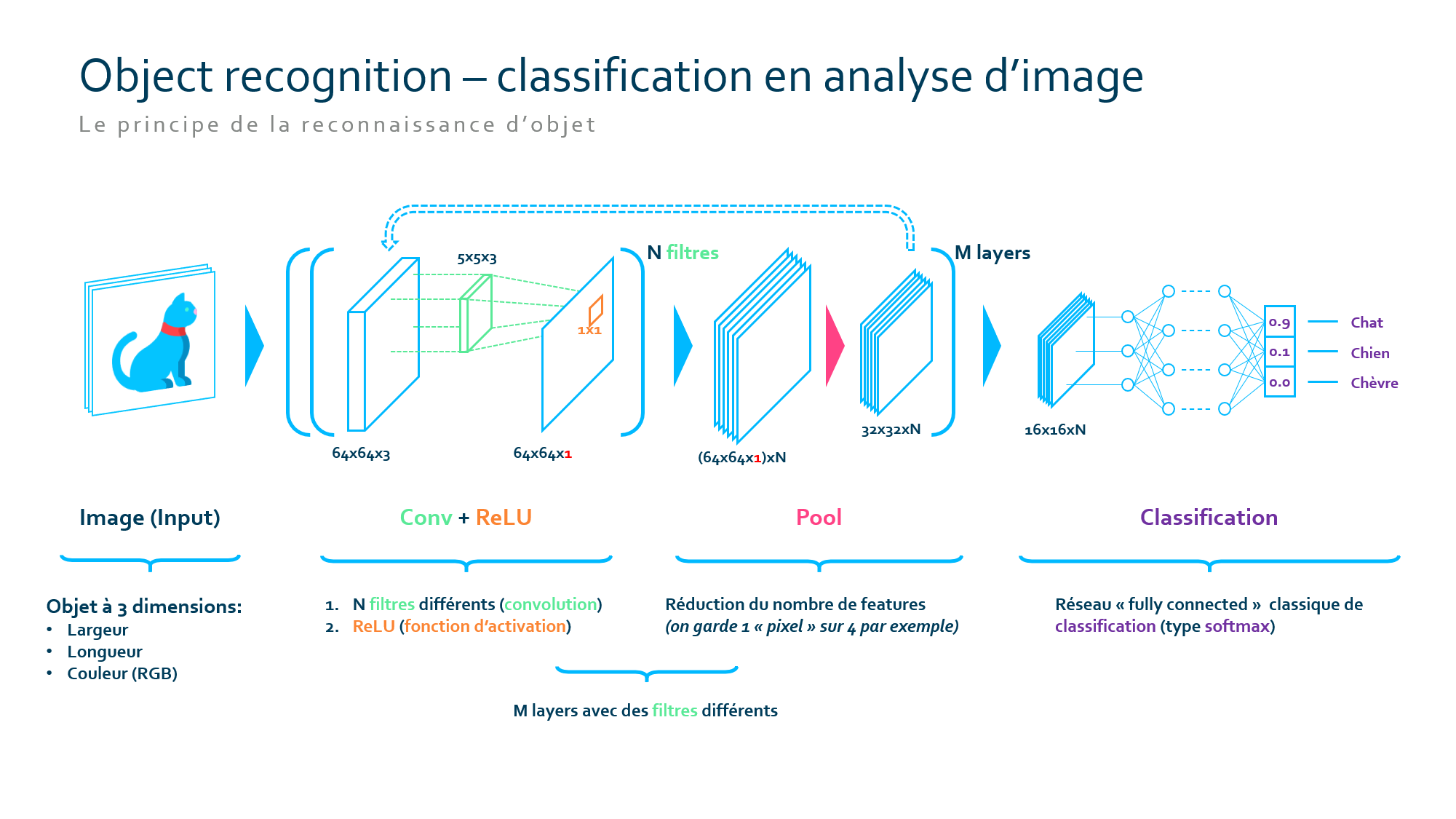

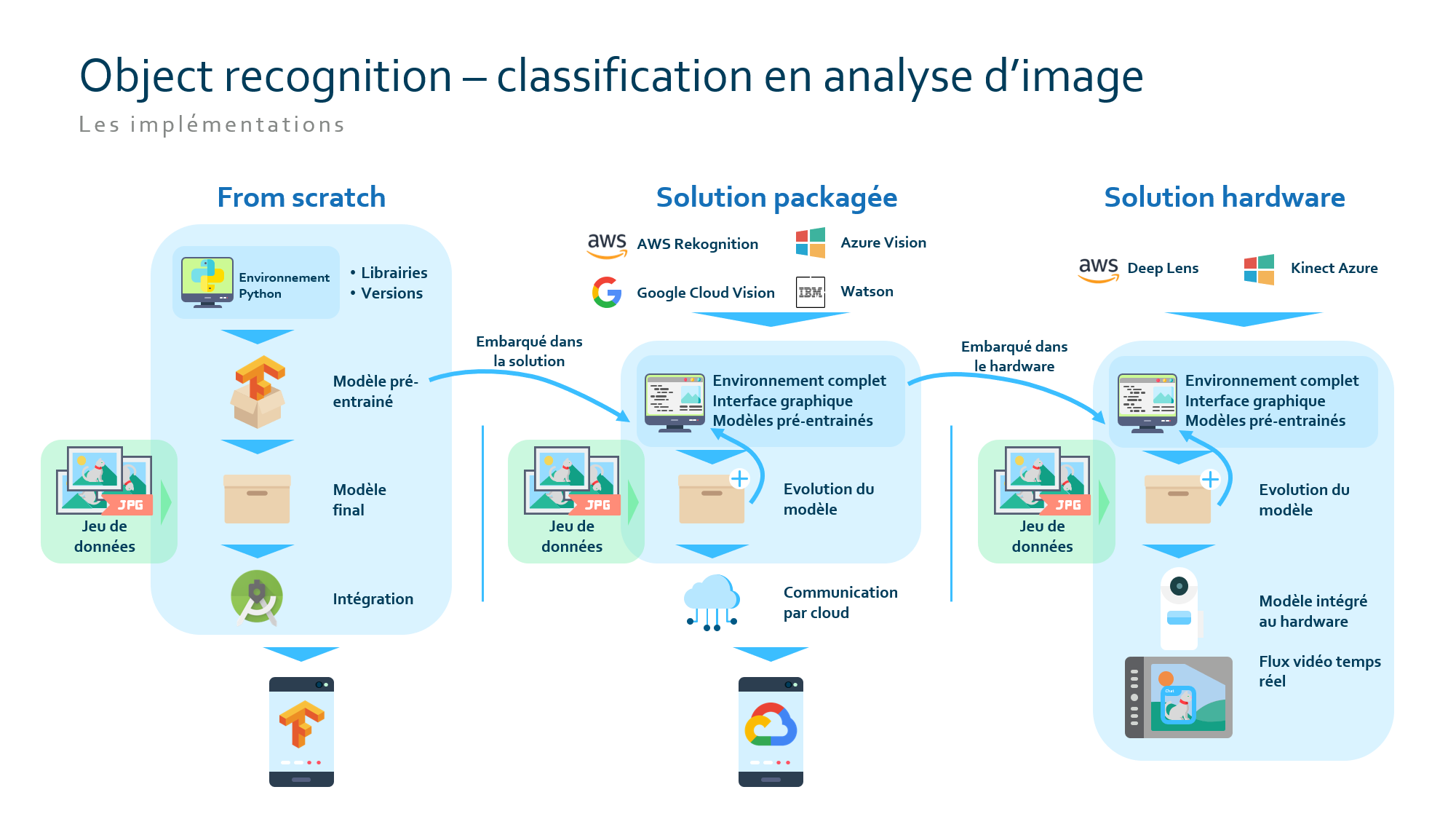
Puis un modèle de reconnaissance d'image a été entraîné sur une problématique interne en guise de POC.
Voirin Consultants
Data Scientist • Avril 2018 - Janvier 2019
Missions :
SIAAP, 2018
Contexte : rédaction d'un manuel d'utilisation de l'information.
Défi :
Le SIAAP dispose, en Ile-de-France de 11 usines de retraitement des eaux usées qui collectent un grand volume d’informations.
La DSI a la volonté de mettre ces données au travail et souhaitait un manuel d’utilisation de la donnée couvrant toute la chaîne de valeur.
Solution :
Le travail a consisté à la rédaction d’un vade-mecum de la données divisé en huit grands axes:
- Organiser
- Collecter
- Stocker
- Protéger
- Traiter
- Valoriser
- Exploiter
- Améliorer
Chaque segment a été développé en donnant les enjeux, les grand principes, l’état de l’art et une illustration (retour client).
Valeur ajoutée :
Ce manuel d’utilisation de la donnée a permis au SIAAP de commencer par poser les premières pierres d’une organisation « data » et de piloter des projets de data science en autonomie.
Caen-la-mer, 2018
Contexte : élaboration d'un schéma directeur des systèmes d'informations pour une communauté urbaine.
Défi :
Dans le cadre de l'entretien de son SI, de le moderniser et d'envisager certaines innovations, la communauté de communes de Caen-la-mer avait besoin d'un schéma directeur informatique pour définir et formaliser l'actualisation de son système d'information.
Solution :
De nombreux entretiens ont été menés auprès des différentes directions de la communauté de communes pour recueillir les point bloquants et les souhaits d'évolutions de chacun. Chacun de ces points a pu être évalué, priorisé et budgété pour réaliser le schéma directeur.
Optimind Winter (Data Square)
Data Scientist & Actuaire • Mars 2016 - Avril 2018
Missions :
MNH, 2018
Contexte : refonte du maillage territoriale des antennes et agences.
Environnement technique : R, H2O, PowerBI
Défi :
La MNH fonctionne par répartition des hôpitaux et établissements de santé entre différentes antennes réparties sur le territoire. Cette répartition n’apportait plus satisfaction car la charge n’était plus répartie de manière adéquate sur les agence.
L’objectif était de créer un outil de visualisation permettant d’observer la répartition de charge pour la piloter de manière optimale.
Solution :
Un outil de pilotage a été créé et déployé grâce à PowerBI pour permettre d’observer les KPI de chacune des antennes et de ses agences en fonction de sa charge.
Cet outil a permis de réaliser un maillage territorial plus fin et adapté à la situation actuelle.
Valeur ajoutée :
Le nouvel outil de pilotage a permis de mettre à jour un maillage territorial qui était daté de faire en sorte que ce maillage soit maintenable dans le temps.
Carte Blanche Partenaires, 2018
Contexte : chiffrage de l'impact financier sur le domaine de la santé du projet RàC zéro.
Environnement technique : R
Défi :
La réforme 100% santé s'accompagne d'un dispositif «Reste à Charge Zéro». Ce dispositif concerne tous les patients ayant besoin de soins dans les domaines dentaires, auditifs et optiques. Grâce aux plafonds imposés sur les tarifs conventionnels et les délais rapides des remboursements (totaux ou partiels) de la réforme 100% Santé, les lentilles progressives, par exemple, peuvent devenir accessibles à l’ensemble des français, peu importe leur niveau de vie.
L'bjectif pour Carte Blanche Partenaires était de connaître l'impact financier de cette mesure sur son réseau de mutuelles.
Solution :
Nous avons utilisé des données historiques ainsi que des données publiques (base Open DAMIR) pour décortiquer les coûts des prestations touchées par le dispositif et en calculer l'impact sur les contrats vendus par les mutuelles du réseau Carte Blanche Partenaires.
Prévère, 2017
Contexte : RPA (UiPath). Développement d'un programme (UiPath) permettant la lecture automatique et le traitement de fichiers PDF.
Environnement technique : UiPath
Défi :
Chaque année à la même période, les équipes de Prévère reçoivent des liasses de documents dont il faut, dans un temps très court, tirer des informations (revenu imposable sur l'année, etc.) et calculer à partir de ces valeurs un score lié à chaque personne.
Solution :
La solution a consisté à développer un programme grâce à UiPath qui automatisé la récolte de ces informations sur des documents scannés aux formats variés, le stockage et le traitement de ces informations.
Valeur ajoutée :
Le logiciel (THOR) mis en place est capable de traiter seul le flux entrant de document et l'intervention d'une seule personne est suffisante pour contrôler le travail effectué. Ce programme a permis de considérablement diminuer la charge de travail pendant une période qui était en principe très chargée.
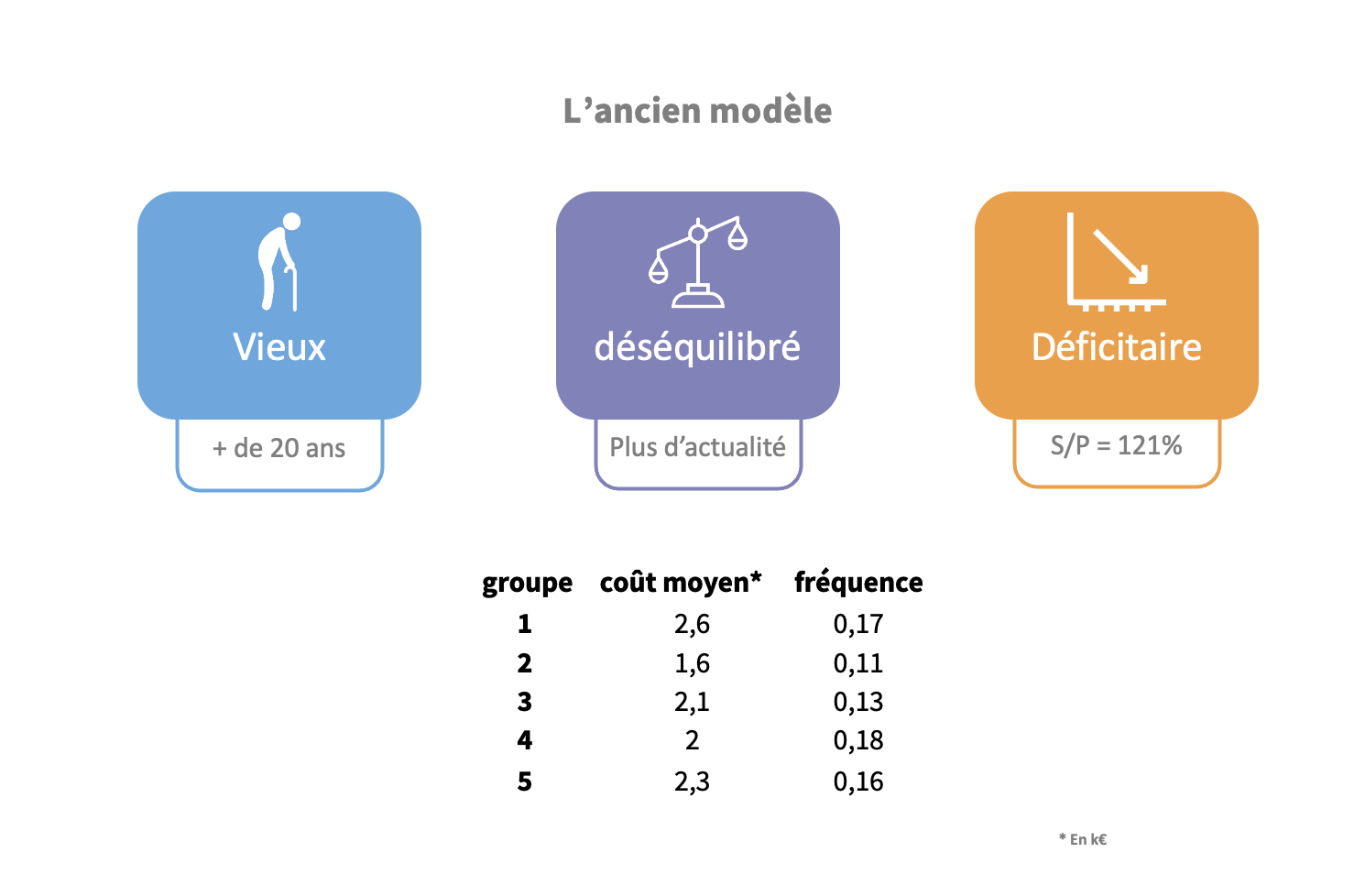
Grand groupe d'assurance, 2017
Contexte : segmentation client.
Environnement technique : R, H2O
Défi :
Dans le cadre d'assurance accident de travail, la tarification utilisée n'apportait plus satisfaction. Le modèle de segmentation et donc de tartification utilisé était daté et devenait déficitaire. Il était nécessaire de resegmenter le portefeuille en prenant en compte les nouveaux secteures et les évolutions des anciens.
Nous avons réalisé un clustering par méthode des k-médoïdes pour obtenir une meilleur segmentation.
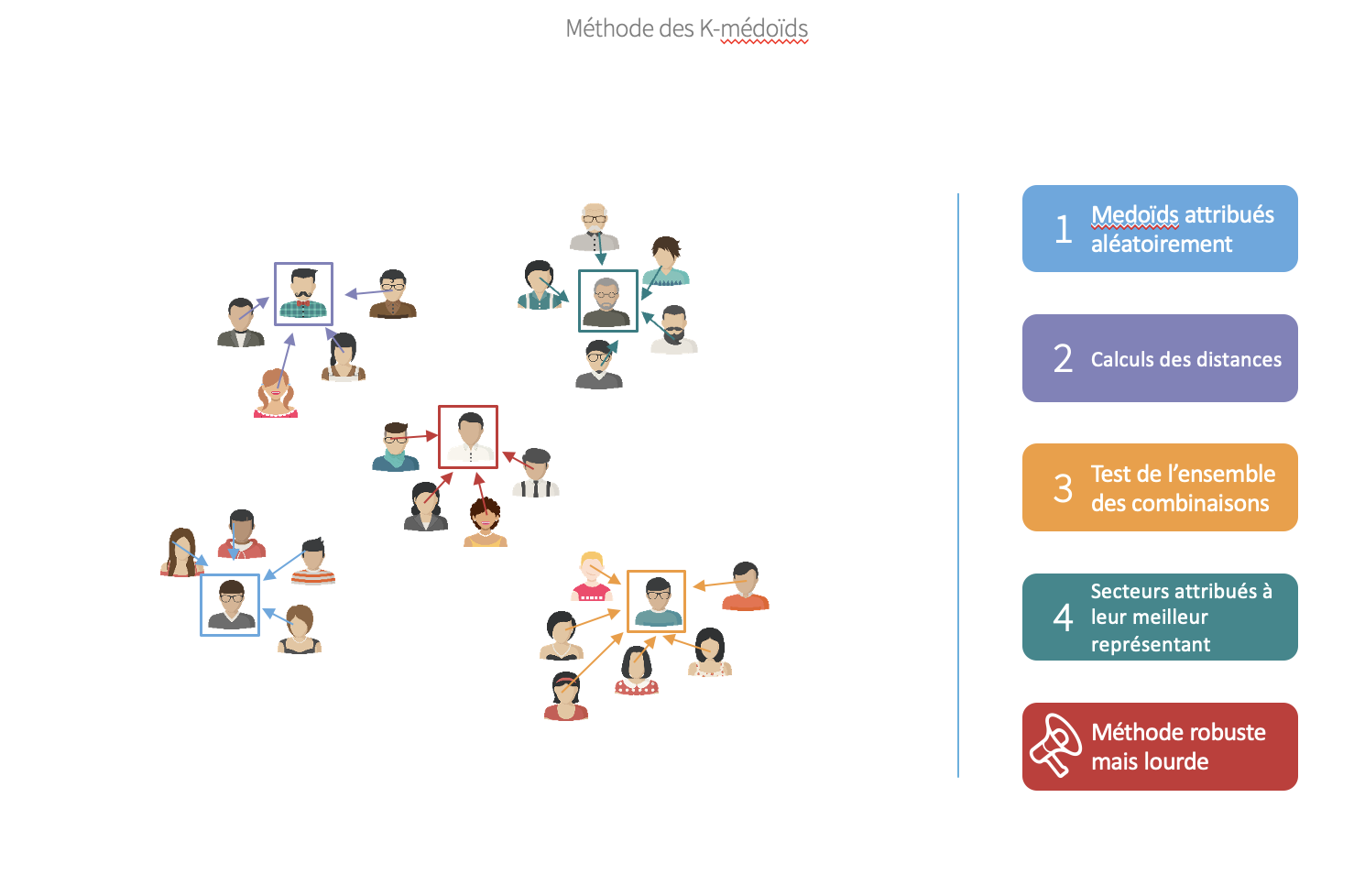
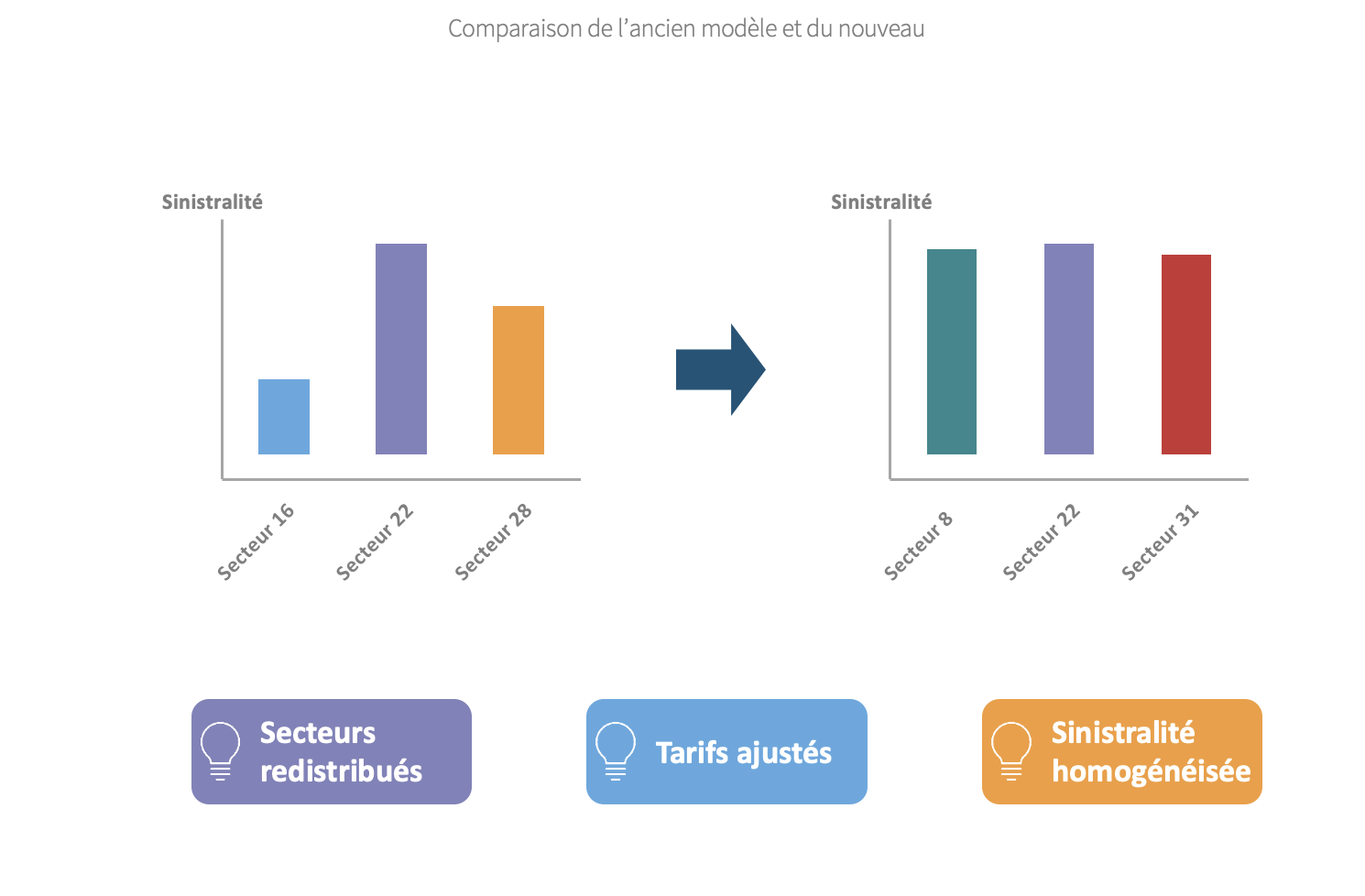
La Poste, 2017
Contexte : modélisation et identification des drivers d'absentéisme.
Environnement technique : R, H2O, Rshiny
Défi :
La Poste emploie un très grand nombres de personnes dans divers secteurs et sous tout types de contrats (salariés, fonctionnaires, etc.). Le groupe La Poste souhaitait connaître les drivers d'absentéisme au sein de ses effectifs et être en mesure de modéliser ce phénomène.
Ma contribution a concerné la production de code pour le retraitement des données et leur bonne utilisation en termes de statistiques et de modélisations.
EURIA, 2017
Contexte : Encadrement de deux bureaux d'étude Data Science en provisionnement et segmentation client.
Environnement technique : R, Rshiny, H2O
Premier groupe : provisionnement
Objectif principal : Réaliser un modèle prédictif du montant total d’un sinistre automobile en fonction de plusieurs critères.
Après avoir retraité et formaté la base, un premier modèle statistique a pu être créé. Il a en suite été enrichi d'une brique de machine learning pour prédire si le sinistre engendra un coût pour l’assureur ou non.
Second groupe : visualisation
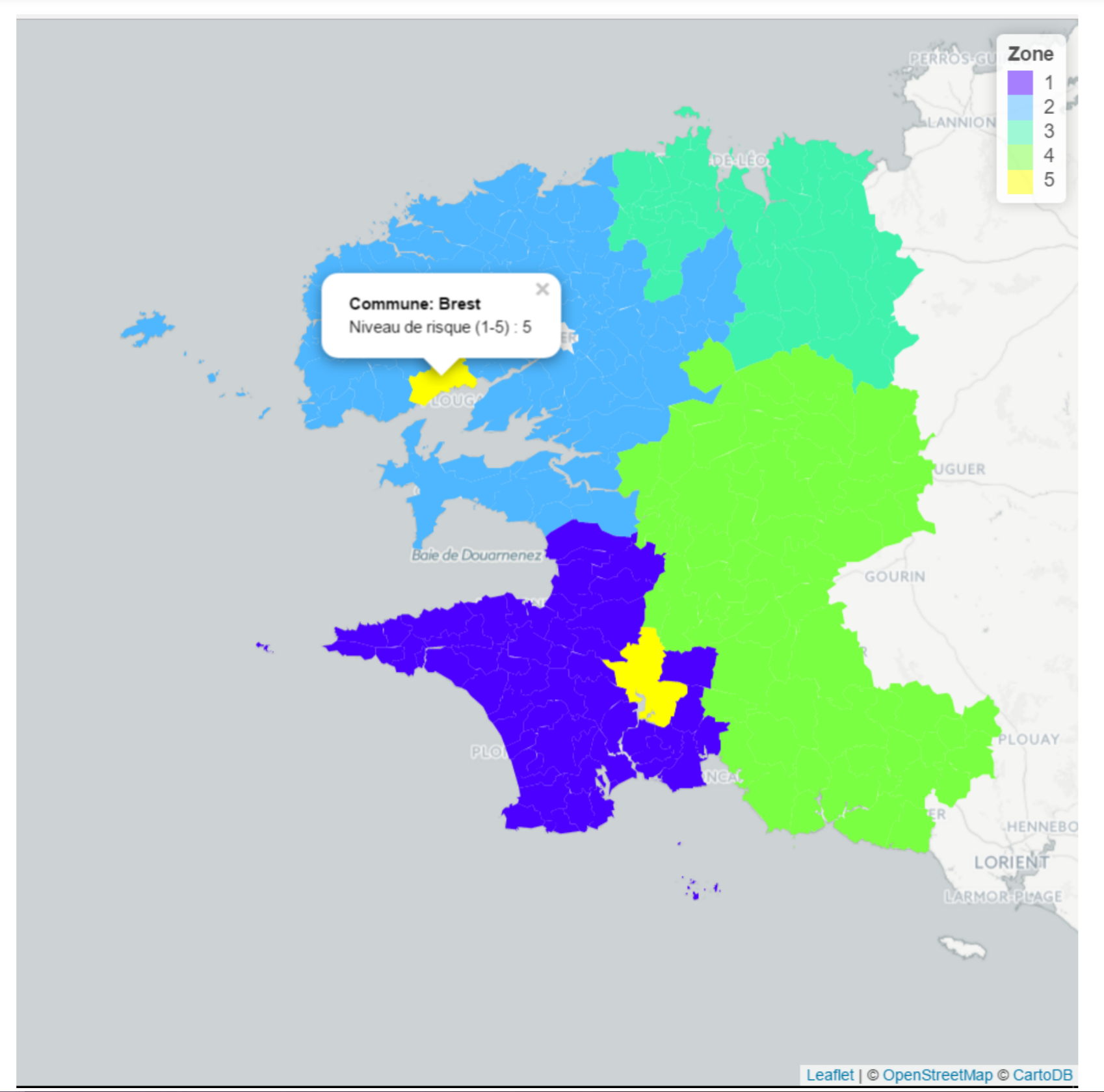
Objectif principal : Création d'un zonier de tarification en assurance habitation.
La création d'un zonier à partir de données de catastrophes naturelles permet à un assureur de définir un niveau de risque par zone (risque inondation ici) et d'appliquer des tarifs adaptés.
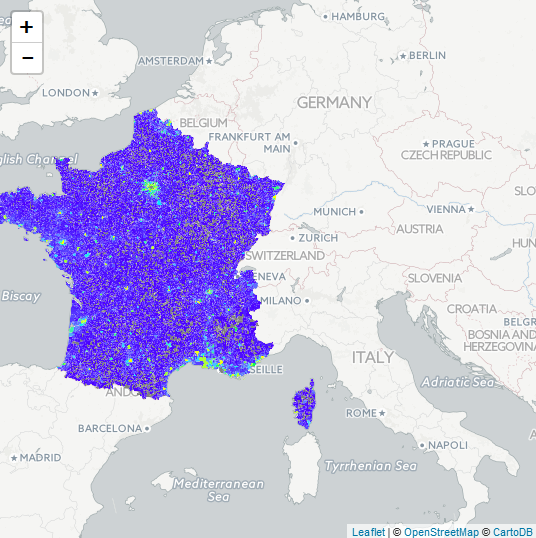
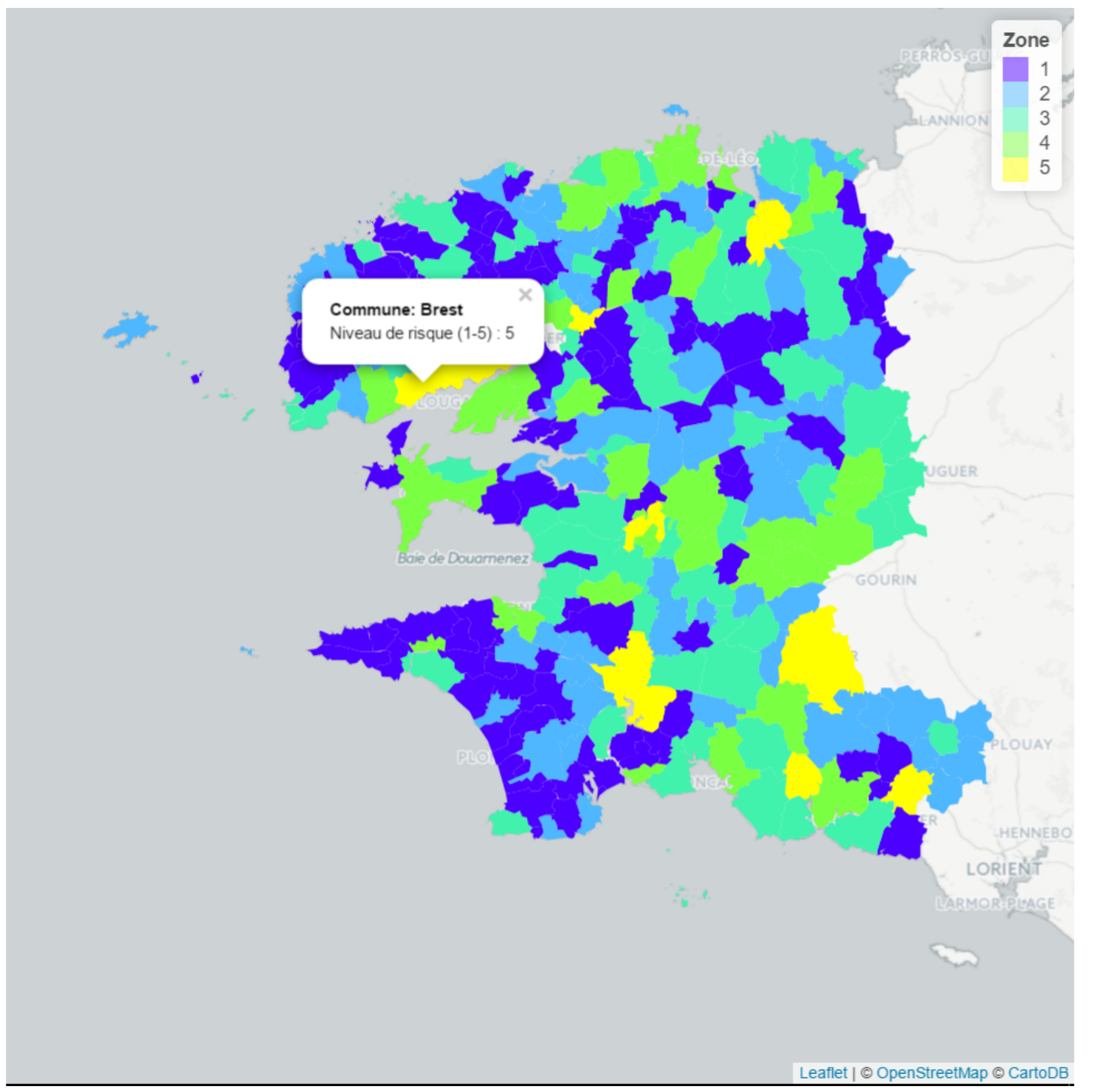
Projet interne, 2017
Contexte : prédiction de migration de rating pour optimiser le SCR de marché en assurance.
Environnement technique : R, H2O, Bloomberg
Défi :
Dans le contexte du calcul de SCR, chaque assureur doit évaluer au mieux ses risques. Les migrations de ratings sont un des drivers principaux du risque de crédit.
Le défi était de modéliser le plus finement possible ces migrations (passage d’un rating AA à un AA- par exemple) pour adapté au mieux l’allocation d’actif aux risques du marché.
Solution :
De nombreuses données de marchés ont été récupérées sur le logiciel Bloomberg, ainsi que des données externes (INSEE).
Le modèle de prédiction a été entrainé avec une fonction de cout asymétrique pour imposer une prédiction prudente : il est plus grave de prédire à tors une migration positive que l’inverse.
Valeur ajoutée :
Le calcul du risque de crédit est fondamental à la bonne santé d’une assurance, ces travaux ont permis d’obtenir une estimation plus fine de ce risque.
Barclay's, 2017
Contexte : modélisation d'écoulements de flux de passifs (dépôts à vue et épargne en banque).
Environnement technique : R, H2O, SQL
Défi :
Dans le contexte du rachat de sa branche France par Anacap, Barclay’s France souhaitait développer son propre modèle d’écoulement de flux de passif.
L’objectif de se modèle est de représenter la dynamique des flux de passifs à court, moyen et long termes pour pouvoir justifier d’un adossement de l’actif optimal.
Solution :
L’acquisition et l’anonymisation des données ont été une part importante du projet. Un travail d’anonymisation a été fait pour respecter le caractère sensible des informations manipulés.
Dans un second temps, le traitement des données et la création d’une base de travail ont été centrales pour identifier des anomalies dans la base et de préparer le terrain pour le travail de modélisation.
Enfin, deux modèles ont été créés, un modèle historique et un modèle issu du machine learning.
Valeur ajoutée :
Création de deux modèles plus fins que le modèle existant permettant d’avoir une meilleur vision de l’écoulement du flux de passif.
Le travail effectué a permis, en plus, de réaliser une nouvelle segmentation client.
Projet interne, 2016
Contexte : réalisation d'un benchmark qualitatif et quantitatif sur le parcours client en Assurance et les innovations.
Défi :
Les banques et assurances sont généralement assez mal perçues du grand public. Les avis des internautes et les notes des services clients sont particulièrement basses dans ce domaine.
Nous avons voulu construire et présenter un état de l'art du parcours client en assurance et les pain points majeurs ainsi que des solutions possibles pour changer cette relation.
Solution :
La première étape a été très empirique et a consisté à vivre ces différents parcours clients en souscrivant chez divers assureurs. Nous avons conclu que le parcours de souscription était bloquant par sa complexité et que le reste du parcours était très décousu, même «mis en suspens» entre deux sinistres.

Une piste proposée a été d'«évoluer vers plus d'assurance connectée», qui a l'avantage de favoriser la prévention en faisant baisser les risques et donc de faire baisser les primes. Les objets connectés permettent à l'assureur de faire un retour sur les habitude du consommateur et même faciliter les expertises et donc de tisser un lien avec le client même en dehors des périodes de sinistre.
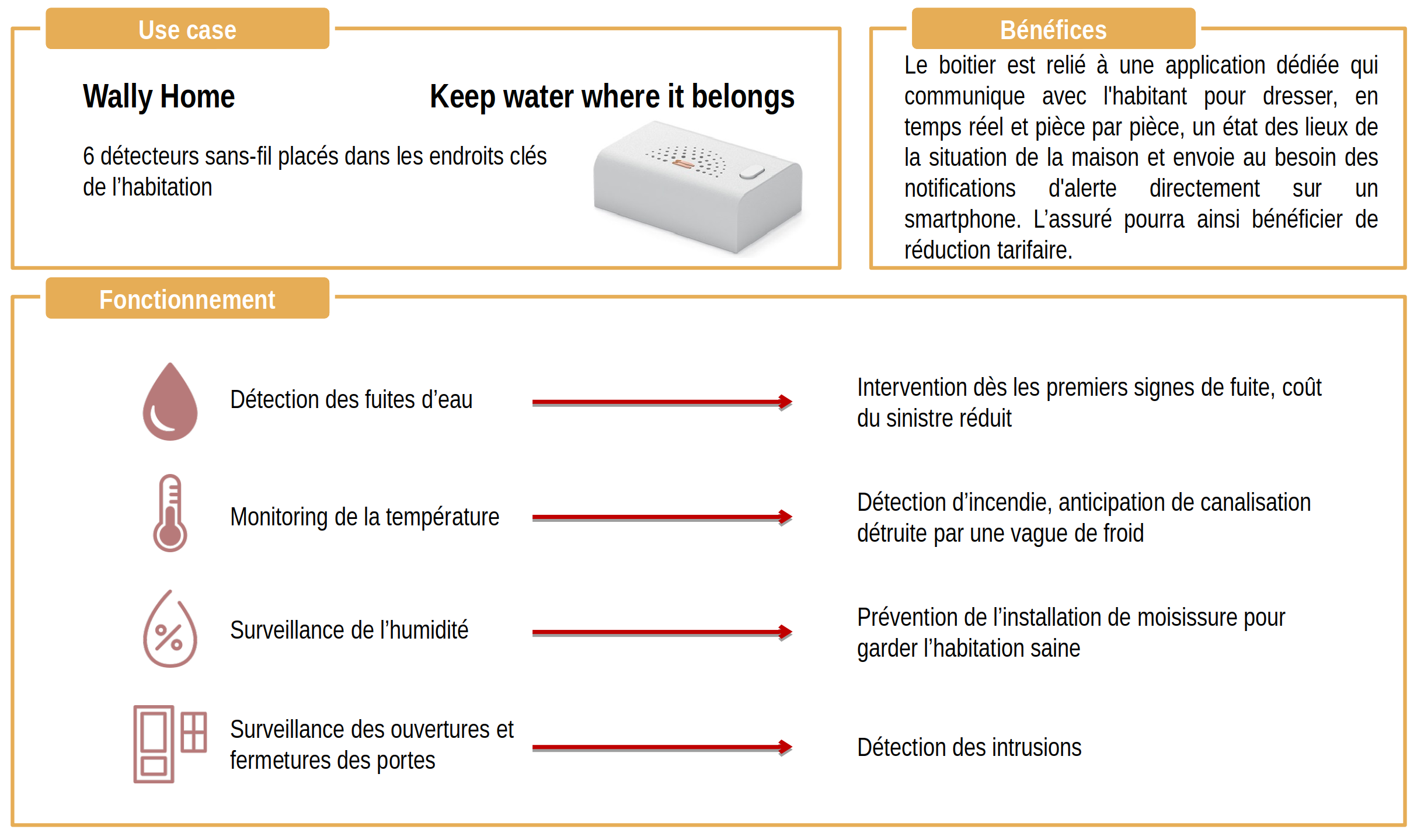
Predica, 2016
Contexte : modélisation de comportement client en assurance vie.
Environnement technique : R, H2O, SQL
Défi :
Predica souhaitait affiner son modèle de prédiction de versements et de rachats d’épargne (assurance vie) en utilisant des méthodes de machine learning.
Pour cela Predica a pu extraire 10 années d’historique (42 millions d’observations) qui ont servies à faire une analyse descriptive des phénomènes de versements et de rachats et de créer un modèle de prédiction de ces phénomènes.
Solution :
Le cœur de la mission a été le retraitement de la base de données. Les profonds changements subis par le SI de Predica sur la période observée ont introduit un grand nombre d’incohérences dans la structure de la base.
La majeur partie du travail a donc consisté a créer des règles de retraitement pour homogénéiser la base et la rendre adaptée à l’apprentissage.
Plusieurs modèles prédictifs ont pu être créés pour modéliser les versements et rachats à la maille client, puis agrégés pour répondre à des problématiques métiers à un point de vu plus « macro ».
Valeur ajoutée :
Les modèles historiques utilisés par Predica n’apportaient plus satisfaction et une meilleur précision a pu être atteinte grâce à notre modèle.
Anticiper précisément les volumes de versements et de rachats sur son portefeuille est fondamental pour une assurance comme Predica car ses calculs de ratio de solvabilité et sa stratégie d’allocation d’actifs en dépendent.
Autres projets
Carte des Vignobles de France, 2023
J'ai scrapé un certain volume de données à propos des vignobles français pour générer cette carte.
Le but de ce projet est d'être éducatif et amusant.
Les technologies utilisées sont : python, request, streamlit et shapely.
Projet personnel - Tennis, 2016
Contexte : analyse de résultats sportifs.
Environnement technique : Python, SQL, RPA
Défi :
Pour pouvoir réaliser une analyse de résultats de tennis, j'ai souhaité récupérer de manière automatisée des résultats de match, les stockés dans une base dédiée et réaliser des traitements dessus pour en tirer des statistiques et des probabilités de victoires de matchs futurs.
Solution :
Les données sont dans un premier temps récupérée par scraping grâce à une méthode de RPA (Request, Beautiful Soup).
Les données sont stockées dans une base de données dédiée (SQL) gérée avec SQL-Alchemy.
Les données sont ensuite retraitées dans python pour créer des statistiques.
Enfin un modèle est entraîné sur les données de matchs pour donner une prédiction sur les matchs futurs.