
Experience
Axa France
Lead Data Scientist • December 2024 - Today
Internal works, 2024 - Today
Data Scientist at the General Secretariat, leading a team of data scientists and analysts.
Technical Environment : Databricks, Spark, Azure Devops, Python
Subject : Engineered and deployed a name matching algorithm to filter our client data base against sanctions and politically exposed people lists among other scenarios of Anti-Money Laundering and Combating the Financing of Terrorism.
Results : brought the 83% accuracy of the base model to 97% with my algorithm on third party benchmarks.
Orange Cyberdefense
Lead Data Scientist (Consultant) • September 2023 - October 2024
Internal works, 2023 - 2024
Technical environment : GCP (Kubernetes, Helm, Terraform), Python (Scikit-learn, PyTorch, MLflow, Airflow, FastAPI, Celery)
Architected and managed a scalable phishing detection infrastructure within a GKE (Kubernetes) cluster using Terraform and Helm for automated provisioning and deployment.
Created a model using text, images and the structure of a webpage to assess its risk.
Set up automation with MLflow and Airflow to version and follow models and orchestrate data tasks.
Results : Orange Cybersecurite.
Kereon Intelligence
Data Scientist • November 2020 - August 2022
Missions :
Hackathon IMA Innovation, 2022
Contexte : Hackathon IMA Innovation.
Results : Second place.
Sujet : "Improvement of a forecasting model based on meteorological data".
🌩🌧Our activity being very strongly subject to climatic hazards, we wish to improve our forecasting model according to them.
The team created a risk zoning France wide for every risk (hurricain, floods, etc.), and a predictive climate model forecasting on 10 days.
Comining both the risk zoning and the model allows to predict the workload for the assistance helpline.
For example, our model allows to predict the staffing necessary for a specific region if it is high risk and we know there is going to be a strong weather event.
Internal project, 2022
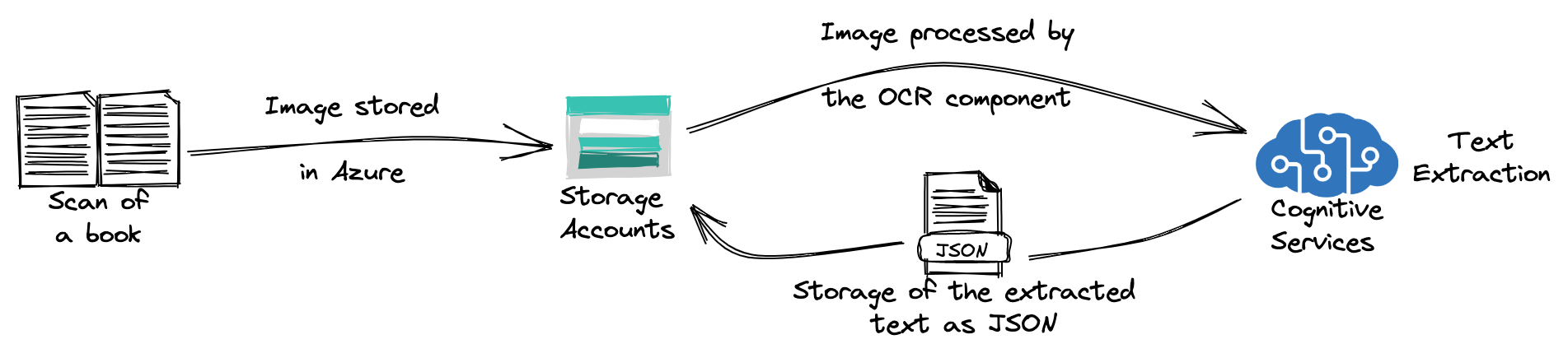
Context : extraction of text from scans of books.
The project consisted of extracting text from scans of books.
The project was realized in a Microsoft Azure environment. The images were first stored in a storage account, then processed with an OCR component. The results were finally saved as JSON in the storage account.
MNCAP, 2021 - 2022
Context : data management and Solvency II.
In order to keep improving their data management strategy MNCAP needed to conduct an audit based around a use case : computing a KPI needed for a reporting in a Solvency II context.
These use cases allowed me to create a data lineage for these KPIs and insure their traceability and accuracy.
MACIF, 2021 - 2022
Context : created a database aggregating several data sources to power a real time dashboard.
Technical environment : SQL, Python
Challenge :
In order to optimize their Policies and Claims management, the Groupe MAIF needed a dashboard aggregating KPIs in real time.
The main challenge was to manage several data entry point from different sources types (Kafka, SQL, CSV) in order to compute said KPIs.
For the sake of optimization, once the data were gathered, every KPIs were computed directly by the database using store procedures so they only had to be loaded in the BI tool (Business Object).
Solution :
The first part consisted in aggregating several data sources of different type.
Secondly, computing every KPI with stored procedures was the main focus of the mission.
Finally, regarding the production launch, some tables needed to be purged daily automatically, triggers needed to be set, etc.
Ocean Hackaton, 2021
Context : Ocean Hackathon event organized by the Village by CA.
Event pageThe Ocean Hackathon is a event focus on innovation for the ocean, the sea and the costal lands in general not only in France but also in many other participating countries.
La Rochelle hosted 8 challenges this year.
I was a Data Coach before and during the event (which spanned over a week-end), my task was to guide and help participants with anything related to data science and management.
CTF, 2021
Context : Creation and coordination of a cyber security event.
A created a set of challenges related to data science for the CTF.
Excelia Business School, 2021
Context : created an online course "Data For Business".
Produced presentations, teaching content and and assessment for a basic data course.
I contributed the following modules :
- Understanding data.
- Data aggregations.
- Data roles and fields.
Territoria Mutuelle, 2021
Context : worked on optimizing the ad words allocation strategy for Google Ads.
This objective is part of a larger project regarding data governance as a whole. Territoria Mutuelle wanted to link Google Ads search terms with the type of client and the quality of their experience.
A full data management audit was conducted through interviews and a functional map & application mapping was produced as a result with a data model.
This first study allowed to identify innovation projects : the improvement of the data architecture and governance.
The purpose of the project was to create a road map and a procure file. The information pipelines were brought together by creating a data centric architecture. Data bridges were created between each data monolith. This worked paved the way for a data culture in order to prepare for future project.
Bak, 2021
Context : data engineering advising / Acting CTO.
The Bak project aims to allow people to easily get in touch with a doctor while traveling for any kind of health issues (general practitioners, chronic disease care). This platform is a traveling companion giving access to features search as easy access to a professional caregiver around the world, information about local geopolitics, sharing content and news with users.
Cerfrance, 2021
Context : created an automated data pipeline from extracting data to build a report.
Technical environment : Python, Flask, GraphQL
Challenge :
Cerfrance needed to create an automated data pipeline to channel data to their new reporting tool.
The main focus of the project was to create a «bridge» between the database and the reporting tool, using automated trigger (using Hasura), extracting data (using GraphQL) and formatting data with regular expressions.
I also created a web service (Flask) so agents could look up a specific client and generated a specific report without relying on a trigger.
Finally I implemented a few more features such as securely saving reports on a server (using FTPS) and automatically distributing reports via email (using SMTP).
France Active, 2020 - 2021
Context : created a risk model in a context of bank loans.
Technical environment : Python
Challenge :
France Active grant loans in the context of business creation for unemployed people. Each project needs to be assessed in terms of risks and scored.
Solution :
My work consisted in creating a data processing pipeline and training a survival model based on data gathered through the years. The pipeline was then integrated in the existing software in order to score new projects.
Added value :
The new model was more accurate and reliable than the older and simpler model which was not good enough anymore.
AddixWare
Data Scientist • November 2019 - November 2020
Missions :
LVMH, 2020
Context : modeling of a physical value (flash point) for cosmetics in order to comply with requirement specifications.
Technical environment : Python, TADA
Challenge :
Modeling the flash point of cosmetic products based on their ingradients.
Solution :
Applying statistical methods and machine learning algorithms to analyze and predict the flash point
MyDataModels, 2020
Project :
Writing of a white paper regarding the evaluation of machine learning models for binary classification, multi-classification and regression.
Covid-19, 2020
Context : Covid-19.
Technical environment : Python
Produced a study about comorbidity regarding covid-19 in order to give facts to base published articles off of. Data were gathered from a Chinese and Mexican hospital giving diagnosis and personal information.
MyDataModels, 2019 - 2020
Challenge :
MyDataModels is developing its own lightweight machine learning software, with a simple interface but allowing to address a vast array of challenges.
The development of the algorithm is in constant growth and is subject of a lot of R&D work.
My role :
I worked on a benchmark for the algorithm in specific cases of an extremely small number of observation and a very large number of features.
A second part of my work was adapting the algorithm to time series analysis.
Added value :
Study about the limitation of the software.
Sanofi Pasteur, 2019 - 2020
Context : data science support with two project.
Technical environment : Python, TADA
Support, help and advising with using the TADA tool in the context of the creation of a patented process of vaccine production and virus DNA/RNA sequencing.
Magellan Consulting
Data Scientist • May 2019 - August 2019
Missions :
Crédit Agricole, 2019
Context : scoping of a complete overhaul of the knowledge management at the scale of the group.
Challenge :
In the context of a knowledge base overhaul at the scale of the group, Crédit Agricole needed a full audit of the storage management and the usage of documents throughout their branches.
Solution :
I realized a large number of interviews with the management and board of each «caisse régionale» and business division to dive deep in the knowledge management at the finest scale. The objective was to map knowledge, detect redundancies of information and document that were not synced or up to date.
Internal project, 2019
Context : in house work on the subject of cognitive services for machine learning : computer vision (Convolutional Neural Network).
Technical environment : Python, TensorFlow, Android Studio
Défi :
Produced a proof of concept in the domain of computer vision in order to apply it to different fields.
Solution :
The first step was to create a benchmark of existing computer solution and make a course on the subject as a first contact with computer vision for machine learning students.
basic principals of CNNs for c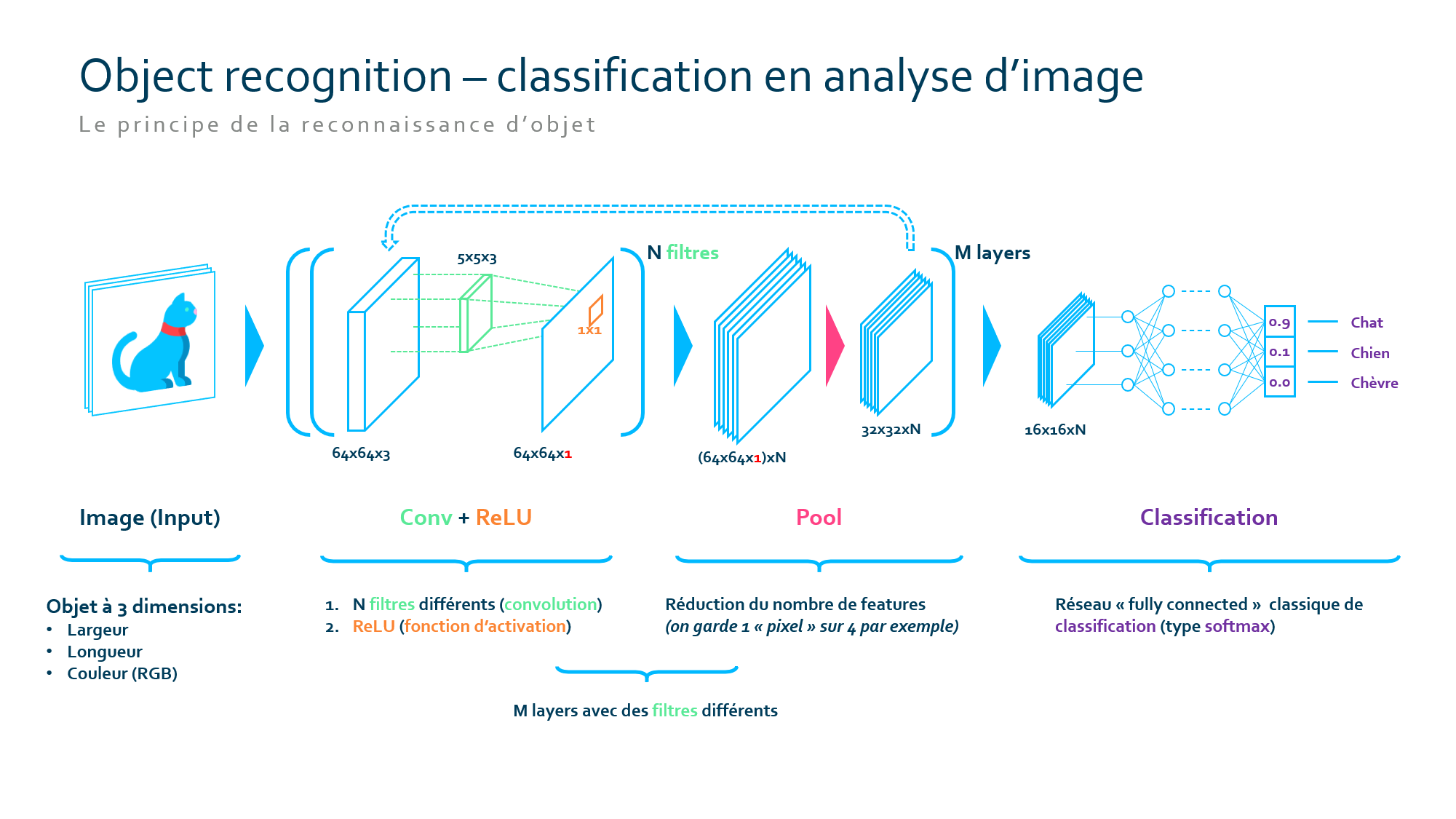

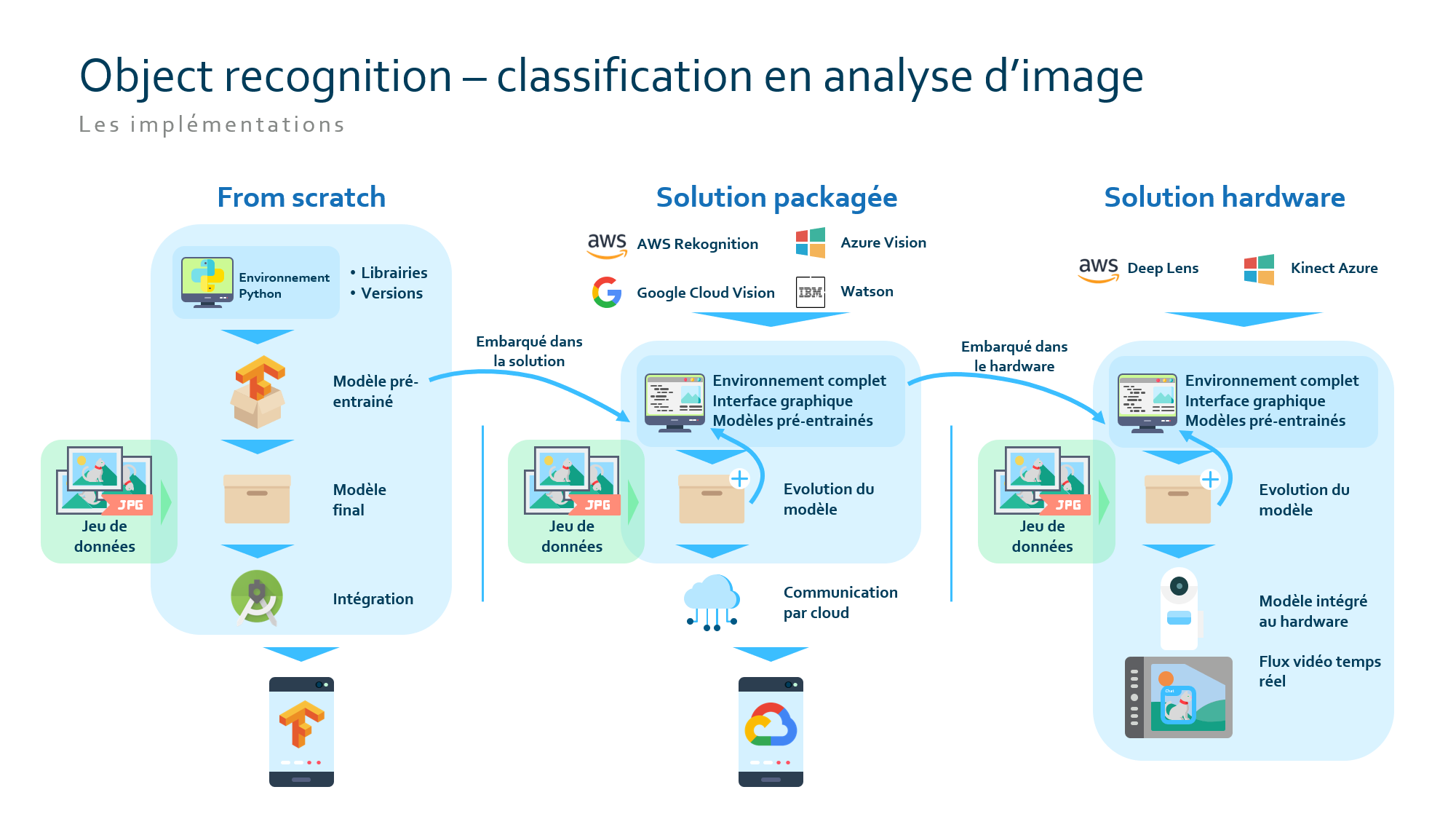
Then, I made a proof of concept with a simple model specifically for an in house use case.
Data Scientist - Consultant
Voirin Consultants - CDD • April 2018 - January 2019
SIAAP, 2018
Context : writing of a data user guide.
Challenge :
The SIAAP owns, all around the Ile-de-France, 11 water treatment plants gathering a large volume of data.
The Information System Department wished to put all these data to work and needed a complete user guide covering the whole data value chain.
Solution :
My work was to write a full user guide divided in height parts :
- Organize
- Collect
- Store
- Protect
- Processing
- Valuation
- Exploitation
- Improvement
Each part was develop throughout its major issues, main ideas, pros and cons, the state of the art and a feedback.
Added value :
This user guide allowed the SIAAP to pave the way for getting data at the center of the organization and lead any future data related project.
Caen-la-mer, 2018
Context : created a Information Technology Master Plan for an urban community.
Challenge :
In order to maintain their Information System, modernize it and envision innovations, the municipality communities of Cean-la-mer needed a Information Technology Master Plan in order to define and put into words the update needed for their Information System.
Solution :
I conducted a large number of interviews with each management and boards of the municipality communities in order to compile every need and pain points. Every of these items needed to be evaluated, prioritized, budgeted in order to compile them in the Information Technology Master Plan.
Optimind Winter (Data Square)
Data Scientist & Actuary • March 2016 - April 2018
Missions :
MNH, 2018
Context : remade the territorial grid for branches and agencies.
Technical environment : R, H2O, PowerBI
Challenge :
The MNH splits the french territory between different branches in order to distribute hospital and health facilities. Their division of the territory was not satisfactory anymore because the workload was not allocated evenly.
The goal was to create a dashboard allowing to visualize the workload in relation to the division to be able to chose an optimal allocation.
Solution :
I created a visualization dashboard with PowerBI allowing to view KPIs for each branches and agencies in relation to its workload.
This tool allowed to create a new and better territorial grid more suited to the current situation.
Added value:
The new tool helped to update an outdated territorial grid and also make it so it is more maintainable in the future.
Carte Blanche Partenaires, 2018
Context : cost analysis of the «Reste à Charge Zéro» health project.
Technical environment : R
Challenge :
The 100% santé reform project was accompanied by a «Reste à Charge Zéro» measure. This measure regarded benefits for dental care, hearing care and ophthalmology. Thank to the ceiling imposed on standard princes and the fast reimbursement times of the 100% santé reform, progressive lenses, for example, can become affordable for most french people, no matter their standards of living.
The goal for Carte Blanche Patenaires was to make a projection of the financial cost of this reform for its cooperative network.
Solution :
We used historical data and public (open source) such as the Open DAMIR database in order to analyze the costs of benefits affected by the project and compute the impact and all policies sold by the Carte Blanche Partenaires network.
Prévère, 2017
Context : RPA (UiPath). Developed a program with UiPath allowed to automatically process PDF files.
Développement d'un programme (UiPath) permettant la lecture automatique et le traitement de fichiers PDF.Technical environment : UiPath
Challenge :
Each year, on a short period of time, the Préfère team receives piles of documents that must be sorted and processed to extract important informations (taxable income, etc.) and compute a score for each person based on these values.
Solution :
I developed a UiPath program to automatically gather the needed information from scanned files, stored and processed all the data.
Added value :
The software (named THORT) is capable of automatically processing any incoming file and only one person is needed to checked the quality of its work instead of enlisting a whole team of 10 people for a month. This program allowed to considerably lower the workload of the team on this time of the year which was previously really heavy.
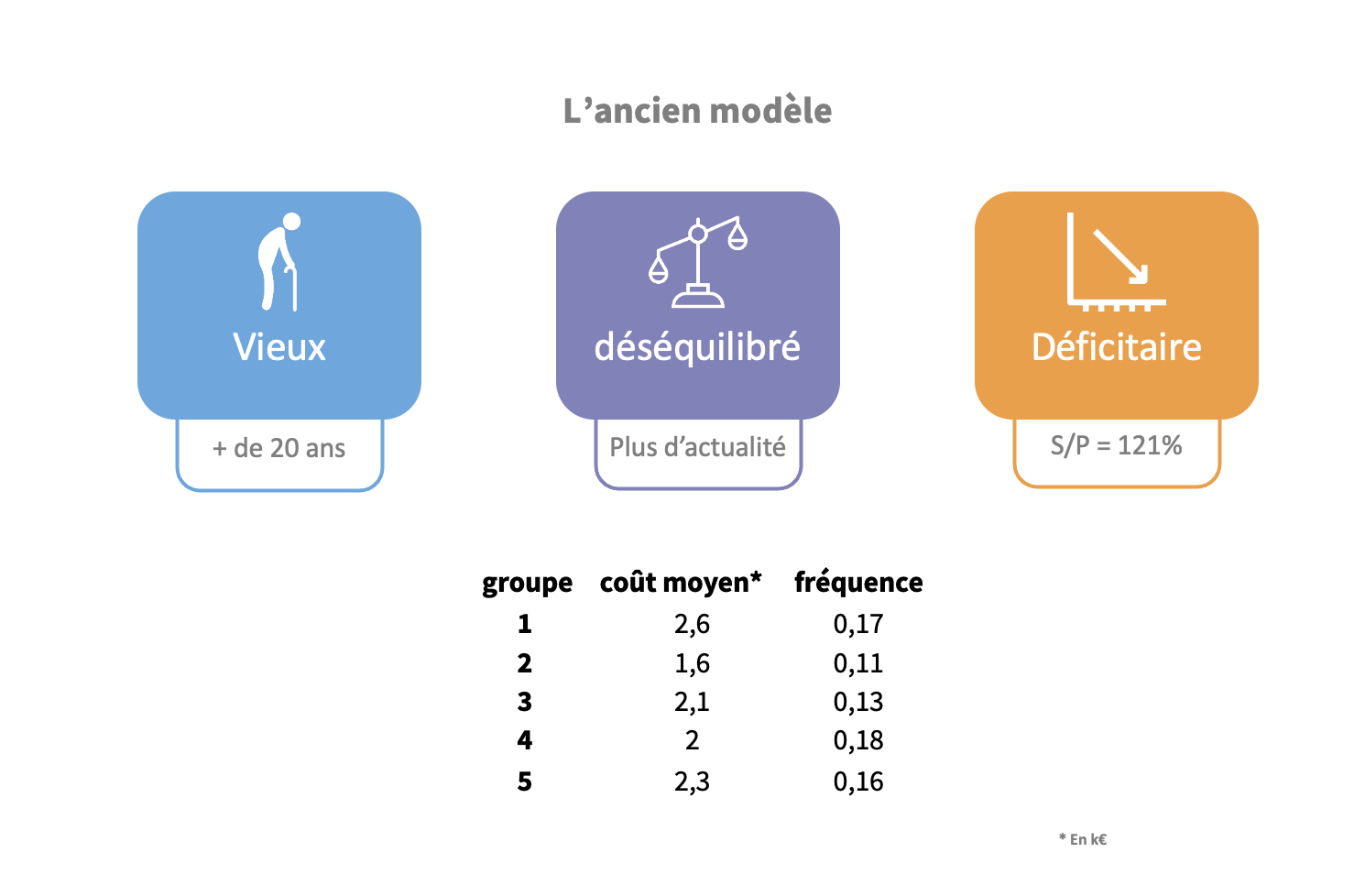
Insurance Group, 2017
Context : customer segmentation.
Technical environment : R, H2O
Challenge :
In the context of workplace accidents, the pricing of the insurance policy was not good enough anymore. The segmentation and the pricing used were old and became unprofitable. A new segmentation was needed, with the news sectors and how old ones evolved.
We used the k-medoids clustering method to get a better segmentation.
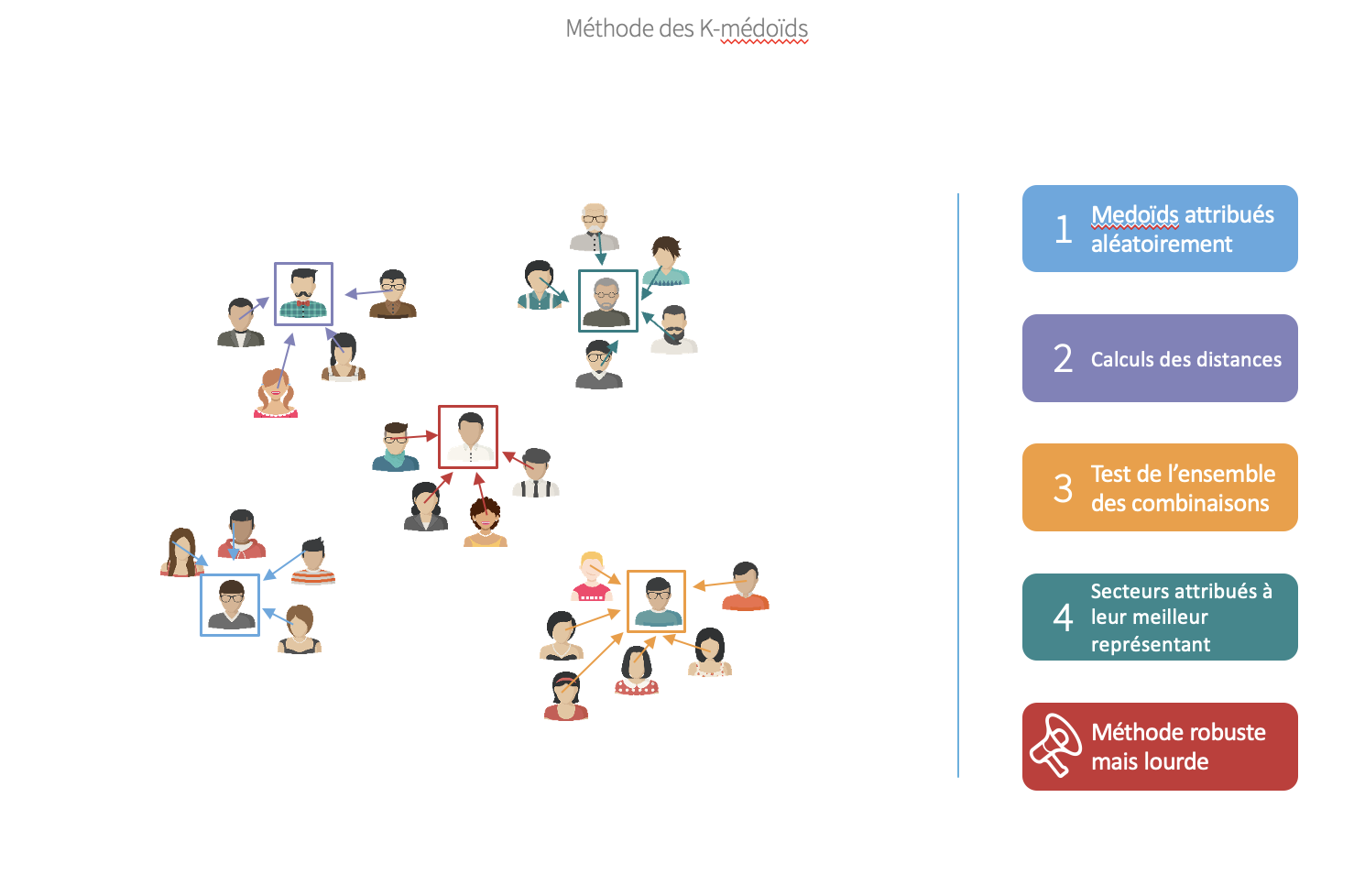
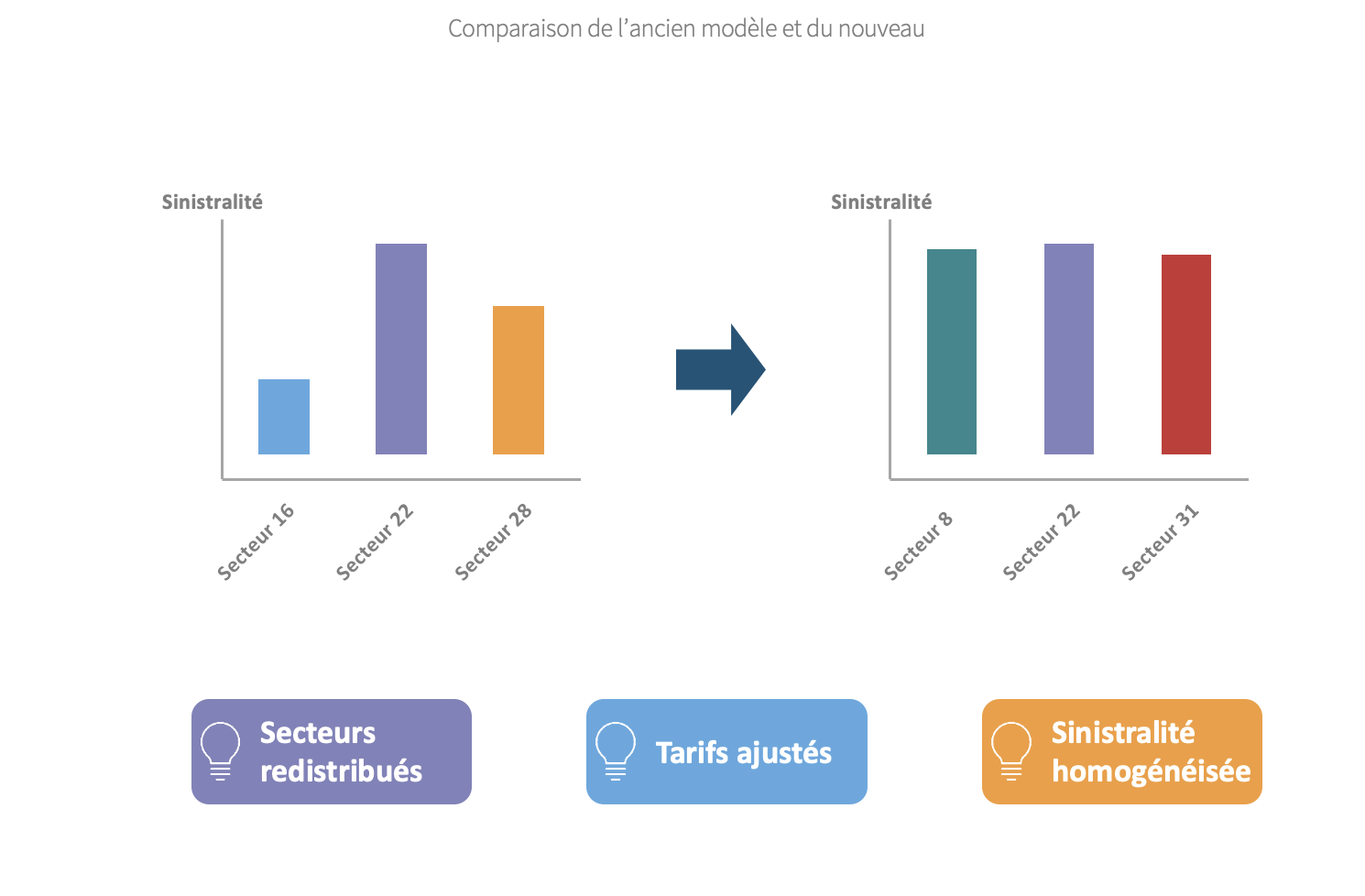
La Poste, 2017
Context : absenteeism modeling and analysis.
Technical environment : R, H2O, Rshiny
Challenge :
La Poste employ a large number of people in several different fields with different contract types (salaried, officials, etc.). The La Poste group wished to conduct an analysis of the causes of absenteeism within its ranks and be able to project this trend.
I processed the data and produced a statistical analysis based on them.
EURIA, 2017
Context : helped and accompanied data science study groups on two subjects.
Technical environment : R, Rshiny, H2O
First group : provisioning
Main objective : make a predictive model of the total amount of claims in auto insurance based on several factors.
After processing the database, a first model was created. It was then enriched with machine learning techniques to get better results.
Second group : visualization
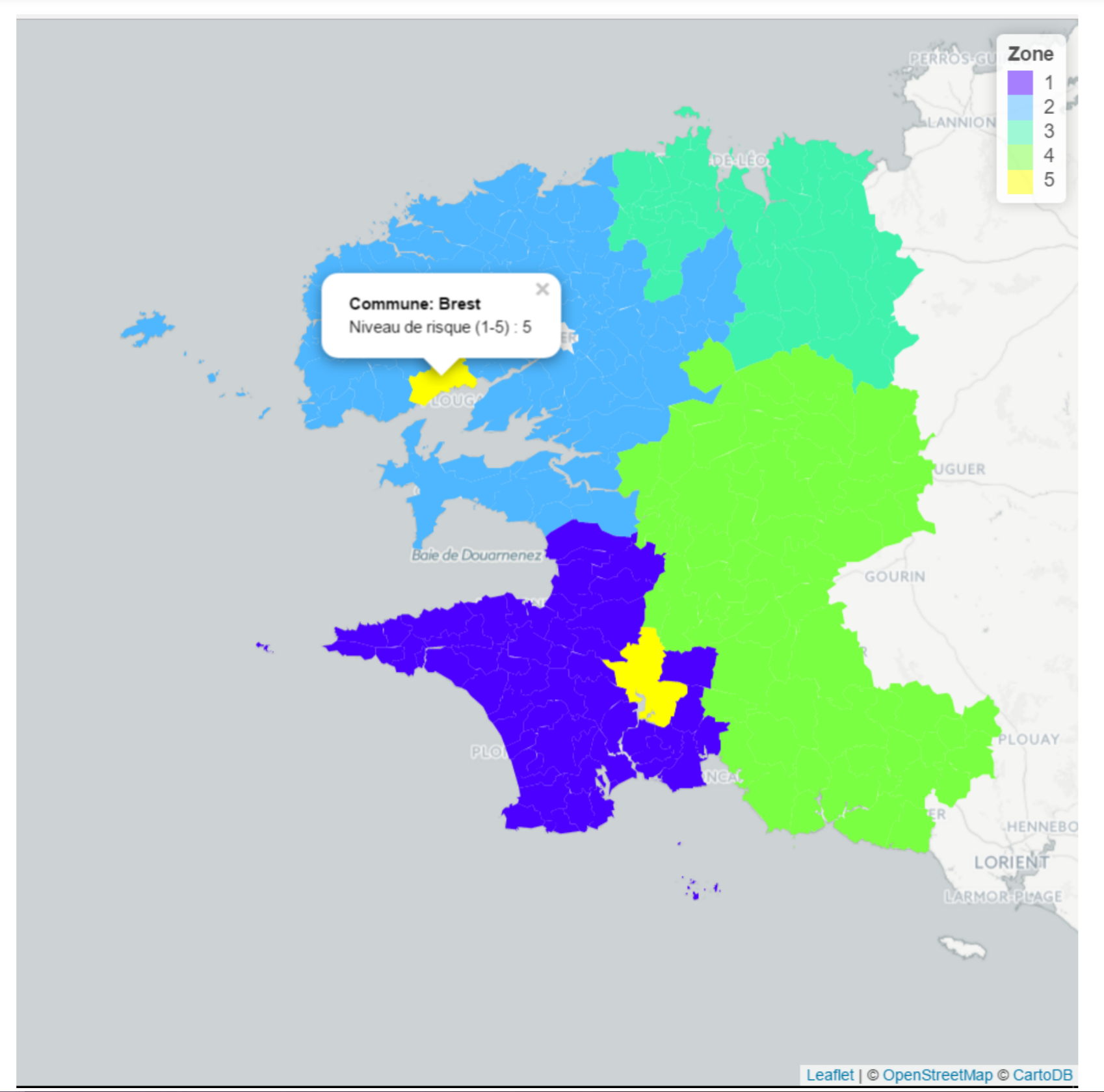
Main objective : creating a risk map for home insurance.
The creation of a risk map based on historical data allowed to define more precise prices per zone and apply more fair premiums.
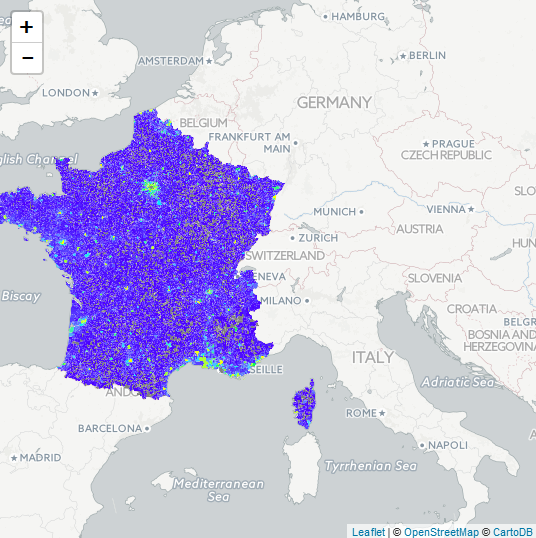
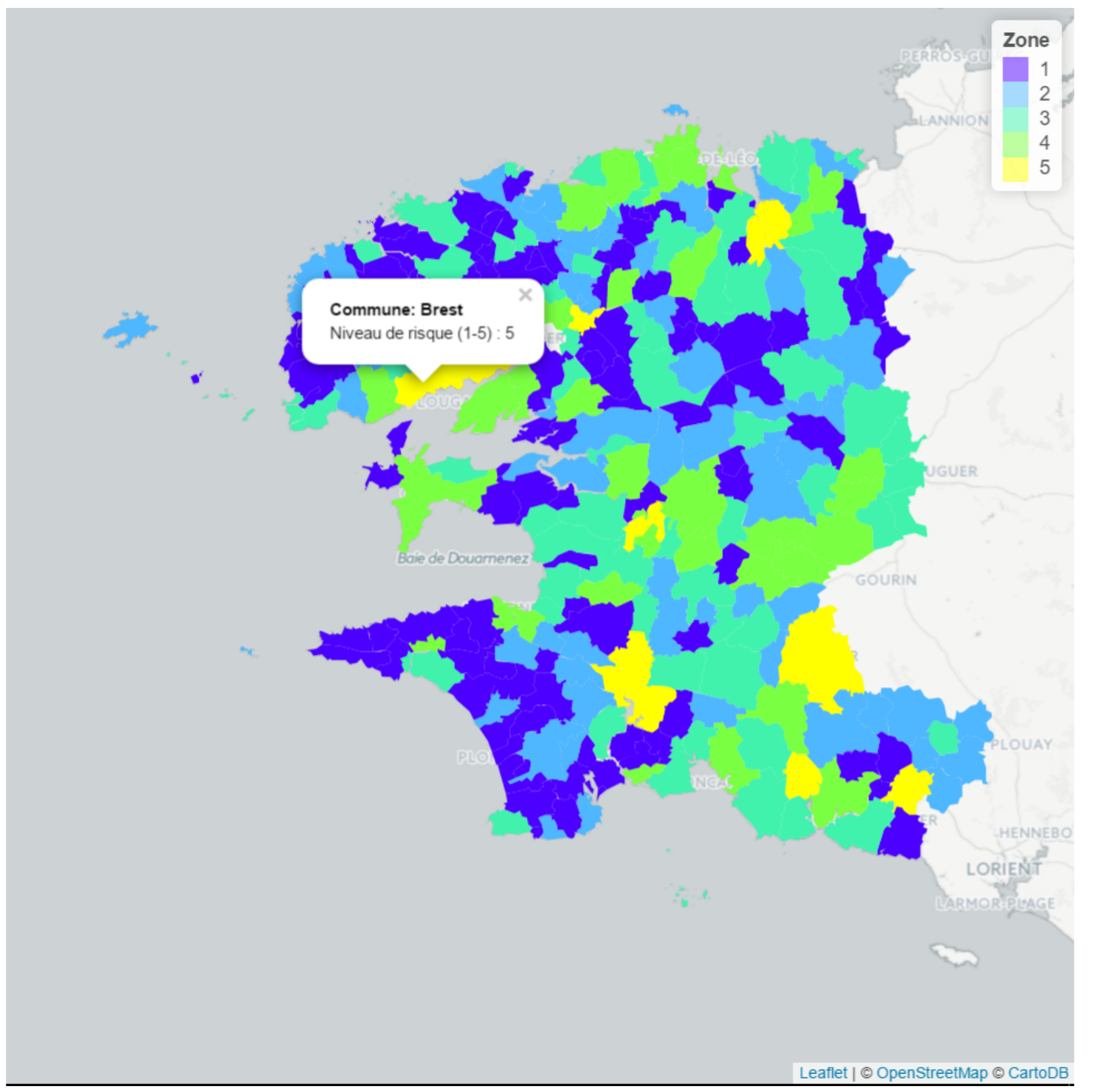
Internal project, 2017
Context : credit rating migration modeling in order to optimize the Solvency Capital Requirement (SCR).
Technical environment : R, H2O, Bloomberg
Challenge :
In order to measure its SCR best, each insurance company must precisely evaluate its risk factors. The credit rating migration risk is one of the main factor of the credit risk.
The challenge was to create a precise model of these migrations (getting from a AA to a AA- for example) in order to make a wiser allocation in ALM.
Solution :
A lot of data was gathered via the Bloomberg software dans also from open sources such as the INSEE website.
The model was trained with an asymmetrical cost function in order to force safer predictions : it is more concerning to be wrong about a positive migration than the opposite.
Added value :
Precisely computing this risk in fundamental for any insurance company. This work allowed to get a better, finer result than when using more standard methods.
Barclay's, 2017
Context : liability cash flow (deposit and savings accounts).
Technical environment: R, H2O, SQL
Challenge :
In the context of the buyout of its french branch by Anacap, Barclay's France wished to develop its own liability cash flow model.
The objective was to model the short, medium and long term dynamic of the liability cash flow in order to optimize their ALM strategy.
Solution :
Gathering and anonymizing data was an important part of the mission. The data needed to be anonymized in order to respect the privacy of Barclay's clients.
Then the data needed to be processed to be able to detect anomalies and plan ahead the modeling phase.
Finally, two models were created, a simple historical model and a machine learning model.
Added value :
The two models crated were both better than the older, simpler model and allowed to get a better understanding of the liability cash flow.
Once this work was done, I did a complimentary analysis of the customer segmentation.
Internal project, 2016
Context : produced a quantitative and qualitative benchmark on the customer path for insurance and related innovations.
Challenge :
Banks and insurance companies are generally poorly viewed by the public. Internet rating and reviews are particularly harsh in this field.
We wished to build and present the state of the art of the customer path in insurance and major pain points but also think of solutions to better this relationship.
Solution :
The first step was really empirical, and I had to «live» the customer path by asking by asking for a quotation from several insurance companies. We concluded that the customer path could be really slowed by its own complexity and the relationship with the customer was really disjointed between the subscription and the first claim.

A proposed solution to this problem was to evolve towards a more «connected insurance» with can be more advantageous for both parties by lowering risks and thus lowering the premium. IoT allow to monitor risk factors (and lowering them) but also the maintain a better relationship with the customer and easing the process in case of accident by being more present.
Predica, 2016
Context : customer behavior modeling in life insurance (savings account).
Technical environment : R, H2O, SQL
Challenge :
Predica wished to better its predictive model for deposits and surrenders in a context of savings accounts by using machine learning methods.
To achieve this, Predica extracted 10 years of history (42 millions observations) that were used to create a descriptive analysis of the customer behavior and model it.
Solution :
The main point of the mission was to process the large amount of data. The information system went through deep changes on the observed period which introduced a lot of mistake and problem in the structure of the database.
A very large part of the mission was to check and homogenize the rules to prepare the data and clean it.
Several predictive models were created in order to model customer behavior and the best one was selected.
Added value :
Older models were not good enough anymore, a better model was chosen thanks to this mission.
Precisely modeling the volume of deposits and surrenders of very important for any insurance company because its solvency ratio depends on it.
Other projects
French Wine Map
I scraped a good amount of data about french wines and generated this map with them.
The purpose of this project is to be educative and fun.
The technologies used are : python, request, streamlit and shapely.
Personal project - Tennis
Context : sports results analysis.
Technical environment : Python, SQL, RPA
Challenge :
In order to analyze tennis games results, I wanted to gather data automatically, store them in a database and process them to get insight and win probabilities.
Solution :
Data were gather firstly using scraping methods (Request, Beautiful Soup).
Then, the date were stored in a database (SQL) managed with SQL-Alchemy.
I then used pandas to process data and create statistics.
Finally, I created a model based every game in the database in order to predict future results.